Biologically Plausible, Evolved Image Recognition
Abstract
This is a project to create a general, complete image recognition solution using connected, evolved,
biologically-plausible image routines. The aim of the project is to create a general purpose image recognition system
that uses a fully automatic training process and requires only basic camera equipment.
This work is being performed by Olly Oechsle, supervised by Dr Adrian Clark.
This page is a brief overview of the achievements to date.
Topics within my research:
Downloads/Demos:
Creating A Biologically Plausible System
 It has been shown that neurons in the brain can perform addition, by combining various inputs into a single output. Experiments on auditory neurons in barn owls [1] have also shown that neurons can multiply two inputs, and therefore must also be capable of division.
It has been shown that neurons in the brain can perform addition, by combining various inputs into a single output. Experiments on auditory neurons in barn owls [1] have also shown that neurons can multiply two inputs, and therefore must also be capable of division.
It is not the aim of this project to create a working model of a neural network, but it should to be biologically plausible. I have selected functions that could easily be used by a mammalian brain, avoiding completely the standard machine vision algorithms. If the program
is able to produce good results using different techniques to standard ones, it may help us understand more about how the human visual system works.
Machine Colour Vision Research
Very little research in machine vision is applied to that of colour vision; most tests are performed on greyscale images. Although colour vision can make problems harder to solve, it also provides much more information about images.
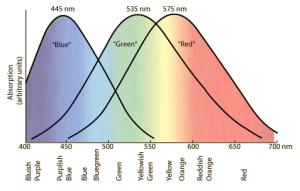 The colour receptors (cones) in the eye respond to different wavelengths of light.
The colour receptors (cones) in the eye respond to different wavelengths of light.
I believe that recognition problems especially are made much simpler when dealing in terms of colour. Instead of trying to describe precisely
the shape of the back of a car, you could create a system to recognise two red areas (brake lights), with a yellow area somewhere in between (number plate).
If you are dealing only in greyscale, this problem becomes much harder.
I am also investigating means of exploiting features of colour that make images much easier to understand.
Once again taking inspiration from natural physiology, it is known that the human eye has approximately 60% ‘red’ cones, 38% ‘green’ cones and 2% ‘blue’ cones.
The human eye's predominant red/green vision makes it a lot easier for the eye to distinguish between red/yellow things (prey or food), from green things (trees, bushes) [2].
Additionally, increasing red/green contrast removes shadows (which exist primarily as a result of blue light reflected from the sky [3]),
making it easier to recognise whole objects. I am presently investigating how the use of different colour spaces and modelled 'eyes' may improve the effectiveness and efficiency of vision software.
Genetic Programming (GP)
Genetic Programming is a means of solving problems by means of simulated natural selection.
Essentially the computer automatically creates a number of programs to solve the problem you set, and finds the one which comes
closest to an acceptable solution. A subsequent ‘generation’ of individuals is created, using the biologically inspired ideas of
genetic crossover and mutation, and so the process continues. While GP is simply a search methodology, it can create novel solutions for problems, will always
detect flaws in your training data, and makes it possible for non-experts to create software.
I am using the ECJ (Evolutionary Computing for Java) toolkit.
Segmentation
Photography is the process of combining a number of different objects onto a 2D image.
Segmentation is opposite: the process of recovering logically distinct parts from a 2D image.
Segmentation involves extracting object(s) in an image from the background
This often involves distinguishing an object from the background of the image.
This problem can be made trivial by putting the object we wish to see on a plain coloured background, but I would like to produce a system that is functional the real world (see below).
My research has also involved low level routines to distinguish parts of an image in motion relative to the camera (another relatively unexplored area of GP vision research).
Both of these problems have been solved successfully using Genetic Programming simply with a small number of test images.
Pattern Reconstruction for Segmentation
Humans are able to recognise objects easily because we have good understanding about each object in a scene. You can see an object
on a patterned carpet because you can see there is something in front of what you were expecting, even if the object is similarly coloured to the carpet.
The aim of this more intelligent segmentation algorithm is for the computer to learn how to reconstruct a pattern after being exposed to one.
Once it can reconstruct a patter, it also knows what to expect. If what it finds is different, it knows that a pixel is not part of the background.
 |
|
 |
| 1. A very simple pattern which can be coded easily by a computer program, and quickly discovered by GP. |
|
2. The parts of the image that do not match the pattern are obvious to the program, even if the star is the same colour as the pattern. |
This is not only a more clever way of image segmentation; it can glean much more information. Think about looking at exactly how different, a pixel is from its expected version:
- If the pixel is just a little darker than expected, it may be part of the object's shadow.
- The shadow could be discounted from the image to make it easier to recognise
- The shadow can be used to locate the light source.
- The size of the shadow can be used to determine the height of the object, or its distance from the floor.
- If the pattern is still detectable within the image, the computer can deduce how transparent the object is
Scale Invariant Model Based Image Recognition
Once the areas of the image have been discovered that are not background images, they may be counted and then individually applied to a recognition algorithm.
Recognition is not about looking at individual pixels, but at the image as a whole. The recognition system needs to have some
idea of the relative positions and values of different sub objects that make up something recognisable. The first part of the recognition
problem is to discover the shapes and properties of these "sub objects" which make up a "model" that the system can compare
an image to.
Cars have been chosen as they are easy to find, easily recognisable (by humans), and have a great deal of variance between models (colour, shape, etc).
 |
 |
 |
| 1. An average picture of all the car images. Common points such as the rear lights and number plates are easy to see. |
2. Using just the saturation values of the colours allows us to discover the most colourful parts of the image |
3. A simple algorithm can extract the interesting parts of the image, allowing us to contruct a model |
To discover what parts of a car are those common between all models, a "homogenised" image was produced by combining all the
training data together into a single image. An interest operator (operating in a similar way to usual pixel segmentation processors)
was used to locate the most interesting (bright / dark / colourful) areas of the homogenised image (see above).
GP is used to find a rule that can be used to identify all cars using this model. Of a test set of 79 images (half of
cars and half of non-cars), the program was able to sucessfully recognise 77 images (97%) correctly. My aim is 100%.
References
1 "Auditory Spatial Receptive Fields Caused by Multiplication"
Jose Luis Pena, Masakazu Konishi (2001)
Science, 13th April 2001 (vol 292)
2 "Spatiochromatic Properties of Natural Images and Human Vision"
Parraga CA, Troscianko T, Tolhurst DJ (2002)
Current Biology 12, 483-487
3 "On the role of blue shadows in the visual behaviour of tsetse flies"
Steverding D, Troscianko T (2004)
Proceedings of the Royal Society London B (Supplement), 271, S16-S17




